4 Datenerhebung, -aufbereitung und -analyse
Jede Art von Forschung ist auf Daten angewiesen, seien sie mittels Personenbefragungen, medizinischer Messungen, Web Scraping oder interpretierender Analysen von Texten erhoben. Auf Grundlage von Daten können Forschungsfragen beantwortet, Thesen aufgestellt, Behauptungen widerlegt, Narrative untermauert werden. Analysen, die sich mit einem kleinen Set von Quellen bzw. Daten befassen, präsentieren Ergebnisse dabei oft in Form von Synthesen, die sich aus einer vorangehenden Interpretation der zugrundeliegenden Dokumente ergeben. Über das Quellenverzeichnis und entsprechende Anmerkungen im Text wird die Grundlage nachvollziehbar; dass ein bestimmter Abschnitt, ein Satz oder ein Wort auf eine gewisse Weise ausgelegt werden, wird aber auch durch die jeweiligen Forscher:innen selbst beeinflusst – eine Literaturwissenschaftlerin beispielsweise, die über Männerfiguren bei Joanne K. Rowling promoviert hat, wird bei der Diskussion um deren mögliche Autorschaft von The Cuckoo’s Calling (siehe Kapitel 2.2) diesen Text anders lesen und andere Argumente dafür oder dagegen aufwerfen als ein langjähriger Harry-Potter-Fan mit viel Leseerfahrung, aber anderer bzw. weniger formaler Ausbildung. Beide werden fundierte Aussagen treffen und Begründungen geben können, ob und wieso The Cuckoo’s Calling von Rowling verfasst wurde oder nicht; beide werden auf ihre Erfahrung und gründliche Auseinandersetzung mit Rowlings Werk verweisen; und beide werden mit einzelnen Sätzen oder Passagen für eine Sichtweise argumentieren, die von einer dritten Person genau gegenteilig genutzt würde. Die Datengrundlage ist also dieselbe und nachvollziehbar, die Auswertung bzw. die Auswertungsstrategien hingegen sind es nicht mehr, und somit auch nicht die daraus gewonnenen Ergebnisse, die ja auch wieder Forschungsdaten darstellen.
Computergestützte Analysen haben den Anspruch, in allen Schritten nachvollziehbar zu sein und dadurch auch nachnutzbare Daten zu produzieren: Nicht nur die Quellengrundlage, also die Erhebung von Daten und die Erstellung eines Datensatzes, sondern auch alle Schritte von der Datenanreicherung und -verfeinerung über die genutzten Methoden bzw. Programme für die Auswertung bis hin zur Sicherung und Aufbewahrung sollen transparent, gut dokumentiert und nachvollziehbar sein. Zum einen, um die Resultate und die darauf fußenden Aussagen belastbar zu machen; zum anderen, um die gewonnenen Daten zur weiteren Nutzung kostenfrei und offen verfügbar zu machen. Zu den Prinzipien, die bei der Arbeit mit Daten berücksichtigt werden sollten, geht es nochmals in Kapitel 5. An dieser Stelle stehen die konkreten Arbeitsschritte bei der Datenerhebung und -aufbereitung, der Datenanalyse und -sicherung im Zentrum, die in Digital-History-Projekten häufig vorkommen.
4.1 Datenerhebung
Es gibt verschiedene Möglichkeiten, Daten für die historische Forschung zu erheben bzw. zu erstellen, von denen einige im Folgenden kurz angesprochen werden.
Für Zeiträume, in denen Quellen vergleichsweise knapp sind und keine seriellen Daten existieren, bietet sich die Digitalisierung von Texten und deren anschließende Analyse an. Digitalisierung beinhaltet dabei nicht nur die Transformation von einer physischen Quelle in ein digitales Bild, sondern auch die Anreicherung des Bilds mit Layout und Text: Erst durch eine Markierung von Bereichen, in denen Text vorkommt, ist es in einem zweiten Schritt möglich, diesen als solchen zu erkennen und damit maschinenlesbar und auswertbar zu machen. Eine solche Umwandlung vom Bild zum Text ist dabei sowohl für moderne Texte, die als Typoskript vorliegen, als auch für vormoderne Handschriften und Drucke möglich, in lateinischer ebenso wie in arabischer, chinesischer oder japanischer Schrift. Es gibt kostenpflichtige Programme wie den Abbyy FineReader, aber auch Open-Source-Tools mit und ohne Graphical User Interface (GUI). Weit verbreitet ist Transkribus, das viele Funktionalitäten bündelt; die Texterkennung ist ab einer gewissen Menge Seiten allerdings kostenpflichtig, wobei studentische Projekte auf Anfrage unterstützt werden können. Programme, die über die Kommandozeile laufen, gänzlich kostenfrei sind und ebenfalls zahlreiche Funktionalitäten bieten, sind beispielsweise eScriptorium, Kraken, OCR4all, OCRopus oder Calamari.
Zur Extraktion von Daten aus digitalen/digitalisierten Texten existieren verschiedene Möglichkeiten mithilfe kleiner Kommandozeilenprogramme (eher mühsam und schwierig zu lesen) oder mit Packages für Programmiersprachen, für die Geisteswissenschaften vor allem R oder Python (siehe dazu auch Kapitel 2.2). So können beispielsweise aus digitalisierten Telefonbüchern Entitäten, also Einheiten, wie Personen, Straßennamen oder Berufe oder aus alten Theaterprogrammheften gespielte Stücke, beteiligte Schauspieler:innen und verantwortliche Regisseurinnen extrahiert und als Datensätze weitergenutzt werden.1
Der anfängliche Aufwand, der einer automatisierten Datenextraktion vorangeht, und die steile Lernkurve bei der Bedienung mancher Programme können abschreckend wirken. Wenn Sie nur ein Theaterprogramm detaillierter auswerten wollen, sind Sie sicher schneller, wenn Sie die entsprechenden Daten in eine Tabellensoftware abtippen. Wenn Sie aber einen größeren Quellenbestand zur Verfügung haben, der in sich ähnlich strukturiert ist, wie das bei Telefonbüchern oder einer Serie von Theaterprogrammheften der Fall sein dürfte, macht es kaum einen Unterschied mehr, ob Sie zehn oder hundert Theaterprogramme mithilfe eines Skripts analysieren möchten. Zudem können Sie Ihr erstelltes Skript, Ihr kleines Computerprogramm, anderen zur Verfügung stellen oder für ähnlich strukturierte Quellen in einem anderen Projekt nachnutzen.
Wenn Sie mit bereits digitalisierten Beständen aus öffentlichen Institutionen wie Galerien, Bibliotheken, Museen oder Archiven arbeiten wollen (sog. GLAMs: Galleries, Libraries, Archives, Museums), besteht oft die Möglichkeit, Daten über Schnittstellen herunterzuladen.2 Solche Schnittstellen, engl. API (Application Programming Interface), ermöglichen eine Kommunikation zwischen zwei Computern, ohne dass hierfür der Umweg über eine graphische Oberfläche nötig ist. Anstatt also beispielsweise über die Suchmaske der Staatlichen Museen zu Berlin nach Objekten oder Dokumenten mithilfe verschiedener Schlagwörter zu suchen und die Ergebnisse dann einzeln herunterzuladen, kann Ihr Computer mit der Schnittstelle des Museums direkt kommunizieren und mit einfachen Befehlen ganze Ergebnislisten zur Weiterarbeit herunterladen. Für solche Abfragen können ein Kommandozeilenprogramm oder Programmiersprachen genutzt werden, die Abfrage besteht dabei im Wesentlichen aus einer Zeile, wie hier in der Programmiersprache R:
library(jsonlite)
cats <- fromJSON("https://smb.museum-digital.de/json/objects?&s=katze")
Wenn Sie die Schritte nachvollziehen möchten, können Sie R hier herunterladen. Wenn Sie das Programm öffnen, müssen Sie zuerst das Paket
jsonliteinstallieren:install.packages("jsonlite")
Mit “Enter” wird das Paket installiert. Dann können Sie die zwei Zeilen oben eintippen und ebenfalls mit “Enter” ausführen. Die Ergebnisse Ihrer Suche können Sie sich mitcats+ “Enter”
anzeigen lassen.
Das Ergebnis der Suchanfrage nach “katze” wird in der Variable cats gespeichert, und diese kann zur Weiterarbeit in ein Tabellenformat exportiert werden:
write.csv(cats, "docs/cats_smb.csv")
Die Funktion write.csv speichert den Inhalt der Variable cats als csv-Datei3 unter dem Dateipfad “docs/cats_smb.csv” auf der Festplatte.
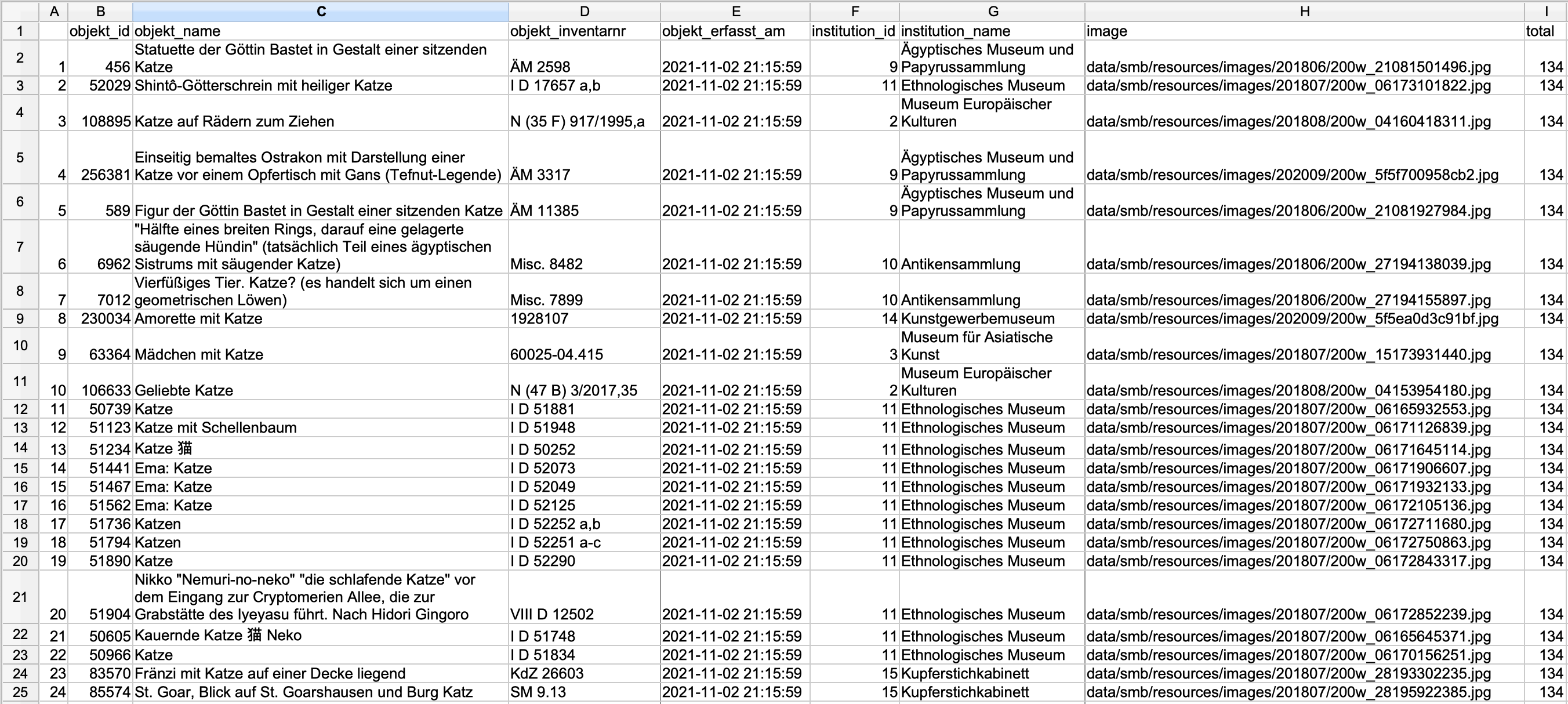
Um Abfragen zu vermeiden, die die Server überlasten, haben die meisten APIs entweder eine Authentifizierung oder eine maximale Trefferanzahl pro Abfrage eingebaut. Beim obigen Beispiel erhalten Sie dadurch nicht die gesamte Trefferanzahl (134, aus der Spalte “total” ersichtlich), sondern nur die ersten 24 – diese Einstellungen haben die Entwickler:innen der Schnittstelle gemacht. Um dennoch alle Treffer mit einer Abfrage zu erhalten, müssten Sie die Dokumentation der API lesen und die Abfrage etwas modifizieren. Wenn Sie das interessiert, finden Sie Details in der Fußnote.4
Wenn Webseiten keine Schnittstellen zur Verfügung stellen, besteht die Möglichkeit, mit Web Scraping an gewünschte Daten zu kommen. Je nach Webseite bzw. Inhalten ist die Rechtslage allerdings nicht ganz klar. Zum Download von Webseiten mit der Programmiersprache Python gibt es eine Lektion im Programming Historian von William J. Turkel und Adam Crymble. Ein weiteres Tutorial zur Datenakquise, von Zach Coble, Liz Rodrigues, Erin Pappas, Chelcie Rowell, und Yasmeen Shorish, findet sich hier.
4.2 Datenaufbereitung5
Bei der Arbeit mit Datensätzen, seien sie selbst erhoben oder von Dritten übernommen, ist es häufig der Fall, dass Informationen fehlen oder uneinheitlich erhoben wurden, was eine spätere Analyse erschwert.
Wenn in einer Umfrage unter Studierenden das Studienfach mit in eine Tabelle aufgenommen wurde, ohne zuvor Werte für diese Kategorie zu definieren, finden sich für “Geschichte” und “Deutsch” vielleicht auch folgende Varianten: “Gesch.”, “Geschichtswissenschaft”, “Geschichtswissenschaften”, “Geschihcte”, “Germanistik”, “Dt.”, “Germ.”. Anstatt zwei Werten für zwei Studienfächer gibt es neun – ohne, dass sich das Fächerspektrum erweitert hätte. Im besten Fall werden solche Varianten schon bei der Erhebung der Daten vermieden, indem eine feste Liste an Werten erstellt wird. Erhält man jedoch einen Datensatz mit verschiedenen Varianten für ein und denselben Wert, muss man diese zusammenführen, um eine saubere Datengrundlage zu erhalten. Sie können entweder mit Strg-R versuchen, verschiedene Schreibweisen zu finden und zu ersetzen; in Tabellenprogrammen wie Excel, Open Office oder Google Sheets können Sie sich einzigartige Werte einzelner Spalten anzeigen lassen und zusammengehörende Varianten zu einem Grundwert zusammenführen; am hilfreichsten, recht voraussetzungslos zu bedienen und dabei auch für große Datensätze nutzbar ist die Software OpenRefine, mit der Sie Daten extrahieren,6 säubern/vereinheitlichen7 und anreichern8 können, um eine für Ihre Forschungsfrage und dafür notwendige Analysen sinnvolle Datengrundlage zu erhalten.
Für Textdaten sind verschiedene Schritte zur Aufbereitung notwendig, je nachdem, welche Methode bzw. Software Sie nutzen möchten. Für die meisten Analysen ist es sinnvoll, mit sogenannten Stopword-Listen zu arbeiten. Stopwords sind Wörter, die vor einer Analyse aus einem Korpus entfernt werden, um aussagekräftigere Ergebnisse zu erhalten, gerade, wenn es um rein quantitative Methoden zur inhaltlichen Erschließung geht. Stopwords sind Wörter mit grammatikalischen Funktionen, die in großer Zahl in Dokumenten vorkommen, jedoch wenig Bedeutung tragen. Wenn man den unbearbeiteten Text dieses Guides nach Worthäufigkeiten auswertet, hier mit Voyant-Tools, lässt sich nur schwerlich erahnen, worum es geht – “digital” steht auf Platz 12, viel häufiger sind Artikel und Präpositionen. Mit Hilfe einer Stopword-Liste, die die häufigsten nicht-sinntragenden Wörter aus dem Text entfernt, wird der Inhalt klarer:
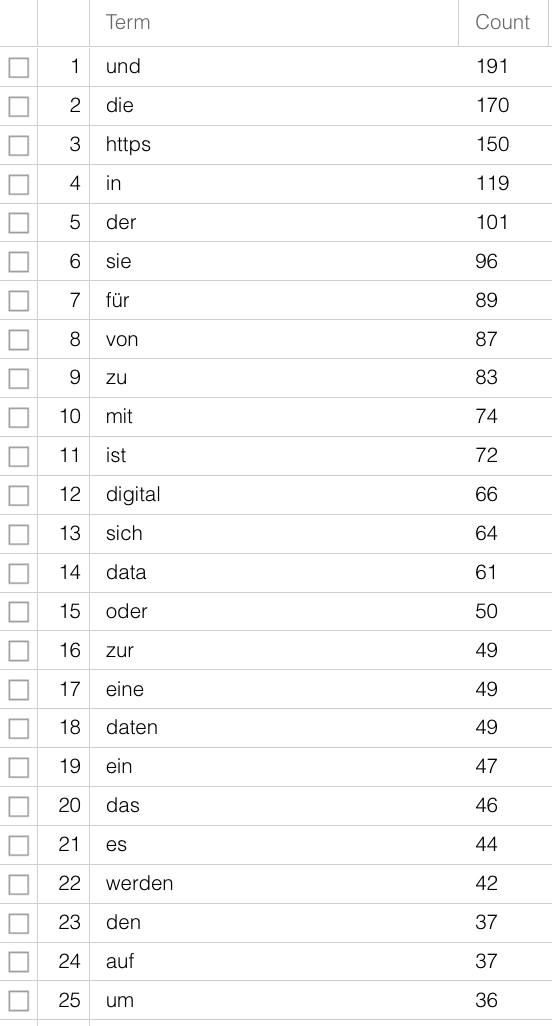
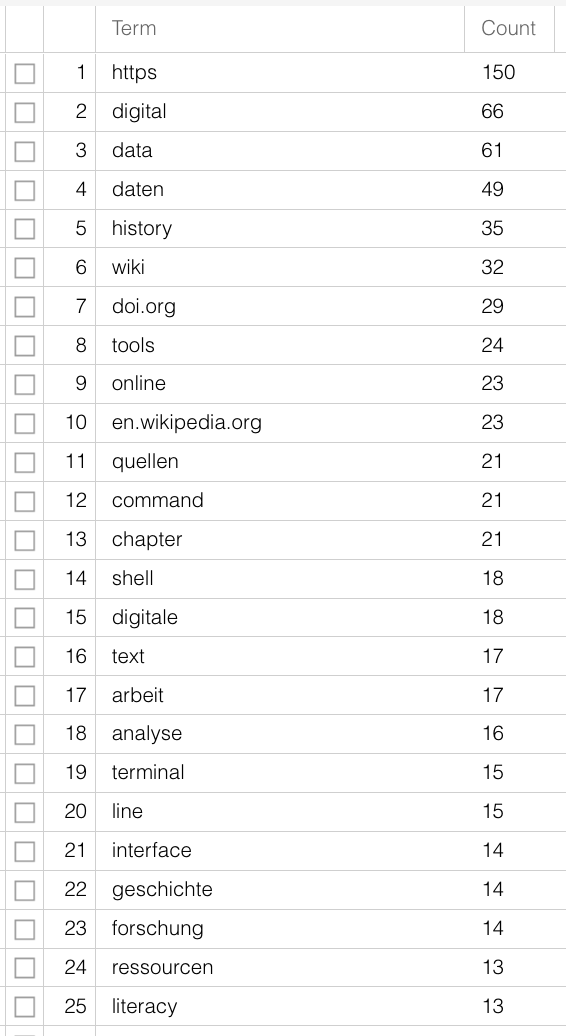
Weitere Schritte beinhalten oft eine Tokenisierung, also die Segmentierung in Einheiten der Wortebene, und eine Lemmatisierung, also die Rückführung von verschiedenene Formen eines Worts auf eine Grundform – aus “ist”, “war” und “sind” wird “sein”. Wie bei den Schreibvarianten der Studienfächer haben die verschiedenen Flexionsformen für die meisten Forschungsfragen keinen Mehrwert und können zur weiteren Analyse zusammengeführt werden. Für solche vorbereitenden Schritte gibt es existierende Software und Packages für Programmiersprachen, sodass hier das Rad nicht neu erfunden werden muss, vor allem für moderne, weit verbreitete Sprachen, siehe auch Kapitel B.3. Schwieriger wird es für nicht-standardisierte Sprachen bzw. Sprachformen, also dialektal geprägte oder vormoderne Texte. Zwar gibt es auch hierfür Programme, die tatsächlich erreichte Präzision muss dabei jedoch je nach Quelle beurteilt werden.
4.3 Datenanalyse
Wenn Sie einen Datensatz zur Analyse zur Verfügung haben, aus selbst erhobenen Daten oder durch Nachnutzung eines vorhandenen, und für Ihre Zwecke aufbereitet haben, folgt (endlich) auch die Analyse. Welche Software oder Methoden Sie verwenden, hängt dabei nicht nur von der Art und Menge der Daten, sondern auch dem Datenformat und vor allem auch Ihrer Forschungsfrage ab. Wenn Sie eine Personendatenbank haben, in der Briefschreiber:innen und Empfänger:innen aufgenommen sind und der Wohnort der Personen bekannt ist, Sie es jedoch versäumt haben, die Datierungen der Einzelbriefe zu verzeichnen, können Sie nur eine räumliche Verteilung, keine raum-zeitliche Entwicklung eines Briefschreiber:innennetzwerks darstellen.9 Wenn Sie aber nur an der örtlichen Verteilung weiblicher und männlicher Verfasser:innen interessiert sind und die zeitliche Komponente für Sie keine Rolle spielt, erübrigt sich auch ein raum-zeitliche Analyse. Bevor Sie sich also für eine Methode entscheiden, sollten Sie sich fragen, zu welchem Zweck Sie Ihren Datensatz nutzen wollen und welche Frage(n) er beantworten soll.
In einem nächsten Schritt sollte über die konkrete Art der Analyse nachgedacht werden, die mit den vorhandenen Daten möglich ist. Unter den zahlreichen Möglichkeiten für die Arbeit mit strukturellen Daten sind für die Geschichtswissenschaften u.a. die Netzwerkanalyse oder die Regressionsanalyse häufig genutzte Methoden. Für textuelle Daten bieten sich ebenfalls verschiedene Arten der Analyse an, darunter beispielsweise Auszählungen von Worthäufigkeiten als Teil der Stylometrie/Zuschreibung von Autor:innenschaft (siehe Kapitel 2.2), Topic Modeling als statistische Methode zur Identifizierung wiederkehrender Themen in größeren Textbeständen, oder Sentimentanalyse, um Stimmungen, Gefühle, Bewertungen aus Textpassagen zu extrahieren. Wenn Sie über georeferenzierte Daten verfügen, können Sie verschiedene Analysen mithilfe von GIS (Geographic Information System) durchführen und visualisieren.
Ob Sie für Topic Modeling ein eigenes Skript schreiben oder vorhandene Software nutzen, ob Sie Regressionsanalysen selbst durchführen oder auf Webseiten durchführen lassen, ist dabei Ihre Entscheidung; oftmals ist das Nutzen vorhandener Webangebote für erste kurze Analysen sinnvoll, um zu überlegen, ob die vorgesehene Methode überhaupt sinnvolle Ergebnisse liefern kann. Für größere Projekte, in denen komplexere Analysen über einen längeren Zeitraum durchgeführt werden sollen, bietet sich die Arbeit mit Programmiersprachen schon allein deswegen an, weil so ein sehr hohes Maß an Anpassungen von vorhandenen Funktionen für die eigenen Zwecke und die völlige Kontrolle über die eigenen Daten ermöglicht wird. Eine Auflistung häufig genutzter Tools für die historische Arbeit findet sich in Kapitel B.3.
4.4 Datensicherung
In Kapitel 5 wird es um Fragen zur nachhaltigen Speicherung von Forschungsdaten gehen; an dieser Stelle sei darauf hingewiesen, dass die Sicherung von Daten am besten auch mit einer Versionierung und mit einer Dokumentation einhergeht. Datenversionierung hat den Vorteil, dass Schritte wieder rückgängig gemacht werden können, Datensätze in unterschiedlichen Stadien gespeichert und für eine spätere Weiterarbeit genutzt werden können und einzelne Schritte einzelnen Projektmitarbeiter:innen zugeschrieben werden können. Zusätzliche Versionierung geht dabei über die Funktionalitäten von Backup-Programmen oder Cloudspeichern wie Dropbox oder Switchdrive hinaus, und für Einzelprojekte wie auch für kollaboratives Arbeiten hat sich in der Wissenschaft wie in der Wirtschaft git etabliert, häufig in Kombination mit Daten-/Coderepositorien auf GitHub. Die meisten von Ihnen werden vermutlich keine eigenen GitHub-Repositorien anlegen, aber das System dennoch irgendwann nutzen, am ehesten durch den Download von dort zur Verfügung gestellten Daten – die Textdaten für diesen Guide liegen auch in einem GitHub-Repositorium. Die Dokumentation von gespeicherten Daten schließlich beinhaltet Informationen zur Entstehung des Datensatzes: Wie und von wem wurden die Daten erhoben? Wie wurden sie annotiert? In welchem Format sind die Daten vorhanden? Welche Software wurde an welcher Stelle benutzt? Was stellen die Daten dar? Die Sicherung von Daten an mehreren Orten, bspw. auf der lokalen Festplatte, in einem Cloudspeicher und auf einem USB-Stick, schützt sicher vor Datenverlust. Eine Dokumentation und die Sicherung in einem Repositorium, einem Langzeitspeicher für Daten, sorgt zusätzlich für Sichtbarkeit und die Möglichkeit zur Nachnutzung von Ergebnissen. Als Fachrepositorien für die Geisteswissenschaften existieren beispielsweise DARIAH-DE oder das DaSCH, es gibt spezialisiertere Repositorien wie AMAD (Mittelalter), oder für alle Disziplinen offene wie Zenodo (fächerübergreifend, betrieben durch das CERN). Sie können Ihre Forschungsdaten dort kostenfrei ablegen, Ihre Urheberschaft nachweisen und die Daten/Publikation mit einem Digital Object Identifier (DOI), also einem eindeutigen und dauerhaften digitalen Identifikator, nachhaltig zitierbar machen.
Ein gut nachvollziehbares Tutorial zur Extraktion von Daten aus Telefonbüchern hat Lindsey Wieck für einen DH-Kurs an der St. Mary’s University in San Antonio erstellt: https://lindseywieck.com/fall_2016_sf/gatheringdatatutorial.html. Derek Miller arbeitet zu Broadway-Vorstellungen, Visualizing Broadway, ein Projekt, das hier beschrieben wird; hier gibt es dazu ein Video in Vorlesungslänge.↩︎
Unter openglam.ch finden sich Informationen zu Schweizer GLAM-Einrichtungen, die offene Daten anbieten.↩︎
comma separated value ist ein Format, in dem einzelne Werte, values, über spezifische Trenner, meist commas, eindeutig abgrenzbar sind und somit in einem Tabellenformat angezeigt werden können, wobei jeder Wert in einer separaten Zelle steht. Tabellensoftware wie Excel, Google Sheets oder Numbers kann csv-Dateien öffnen.↩︎
-
Die API aus dem Beispiel ist so konfiguriert, dass bei Abfragen mit Ergebnissen über 24 Treffern nur die ersten 24 ausgegeben werden; das ist etwas ungewöhnlich, aber wir können damit umgehen, indem wir die maximale Trefferausgabe pro Anfrage auf 10 setzen – diese Zahl ist nicht zu hoch, und wir können gut damit rechnen. Der Parameter für die maximale Trefferzahl kann mit
&breitenat=10eingestellt werden. Den Startpunkt der Ausgabe kann man mit dem Parameter&startwert=ändern. Um also alle Treffer für eine Abfrage zu erhalten, können wir die Ergebnisse in 10er-Schritten abfragen und anschließend zusammenfügen. Damit das nicht zu einer copy-paste-Aktion wird, müssen wir etwas ausführlicher formulieren bzw. mehrere Variablen verwenden. Das hat aber den Vorteil, dass man auf diese Art dann nach jedem Begriff suchen kann.base_URL <- "https://smb.museum-digital.de/json/objects?&s=katze" cats <- fromJSON(base_URL) start <- 0 breite <- 10 iterations <- cats$total[1]%/%10 + 1 endsize <- cats$total[1]-(iterations-1) * 10 cat_list <- data.frame() for (i in 1:iterations){ if(i < iterations){ cat_list <- rbind(cat_list, fromJSON(paste(base_URL, "&gbreitenat=10&startwert=", start , sep=""))) } else { cat_list <- rbind(cat_list,fromJSON(paste(base_URL, "&gbreitenat=", endsize, "&startwert=", start, sep=""))) } start <- start + 10 write.csv(cat_list, "Desktop/cat_list.csv") }Zuerst machen wir den Code übersichtlicher und speichern den Großteil der URL in
base_URL:base_URL <- "https://smb.museum-digital.de/json/objects?&s=katze"
Die Ergebnisse der Suchanfrage werden wieder im Objektcatsgespeichert:cats <- fromJSON(base_URL)
Die Anzahl Durchgänge für eine Abfrage ergibt sich aus derAnzahl der totalen Treffer/10 + 1; die Anzahl der Treffer lässt sich aus der Spalte “total” im Objektcatsentnehmen. In R formuliert man das so:cats$total[1]
Im Katzenbeispiel sind es 134 Gesamttreffer, also(134/10 ohne Rest)+1, also14Durchgänge:iterations <- cats$total[1]%/%10 + 1
Dann setzt man den Startwert auf 0:start <- 0
Und die Maximaltreffer auf 10:breite <- 10
Die letzte Iteration muss dabei nicht die nächsten 10 Treffer abfragen, sondern nur noch 4 (die letzten 4 nach 130):endsize <- cats$total[1]-(iterations-1) * 10
Dann erstellen wir eine leere Tabelle, einen data frame, die wir mit unseren Anfragen nach und nach befüllen. (Bei kleinen Datenmengen kann die Funktionrbindzur Verbindung von Einzeltabellen genutzt werden; bei größeren Datenmengen ist das iterative Verlängern von data frames nicht empfohlen):cat_list <- data.frame()
Wenn wir diese Variablen festgelegt haben, können wir einen Loop, eine Schleife bauen, die unter bestimmten Bedingungen verschiedene Aktionen ausführt:for (i in 1:iterations){
Falls die letzte Iteration noch nicht erreicht ist, wird die Abfrage in 10er-Schritten durchgeführt, wobei der Startwert bei jedem Durchgang um 10 verschoben wird und die Ergebnisse hintereinander incat_listgeschrieben werden.if(i < iterations){cat_list <- rbind(cat_list, fromJSON(paste(base_URL, "&gbreitenat=10&startwert=", start , sep="")))} else {
Sobald die letzte Iteration erreicht ist, werden nicht mehr die nächsten 10, sondern so viel Treffer, wie inendsizegespeichert, abgefragt, in unserem Beispiel 4:cat_list <- rbind(cat_list,fromJSON(paste(base_URL, "&gbreitenat=",endsize, "&startwert=", start, sep="")))}start <- start + 10
Zum Schluss, in diesem Fall nach 14 Iterationen, wird die Tabelle in eine Datei geschrieben:write.csv(cat_list, "Desktop/cat_list.csv")}↩︎ Eine häufige Aussage ist, zur Datenvorbereitung/Preprocessing würde 80% der Arbeitszeit verwendet, zur Analyse und Interpretation blieben nur 20%. In einem Blogartikel von 2020 geht Leigh Dodds diesen Zahlen nach – ganz so dramatisch ist das Verhältnis in Wahrheit wohl nicht.↩︎
Evan Peter Williamson: Fetching and Parsing Data from the Web with OpenRefine, Programming Historian 6 (2017), https://doi.org/10.46430/phen0065.↩︎
Seth van Hooland, Ruben Verborgh, Max De Wilde: Cleaning Data with OpenRefine, Programming Historian 2 (2013), https://doi.org/10.46430/phen0023.↩︎
Karen Li-Lun Hwang: Enriching Reconciled Data with OpenRefine, The Bytegeist Blog 2018, https://medium.com/the-bytegeist-blog/enriching-reconciled-data-with-openrefine-89b885dcadbb↩︎
Ein Großprojekt an der Universität Stanford, “Mapping the Republic of Letters”, hat für das 18. Jahrhundert das Briefnetzwerk europäischer Gelehrter modelliert. Ein Fallbeispiel ist das Netzwerk Voltaires, in verschiedenen Visualisierungen: http://republicofletters.stanford.edu/publications/voltaire/letters/. Dan Edelstein. Interactive Visualization for Voltaire’s Correspondence Network. Letters in Voltaire’s Network [Created using Palladio, http://hdlab.stanford.edu/palladio].↩︎